
Multimodal Multi-image Reasoning Benchmark
*Equal contribution §Core contribution †Project lead
🚀 [2025-05-31]: We released MMRB, a benchmark for multimodal multi-image reasoning. 🥳
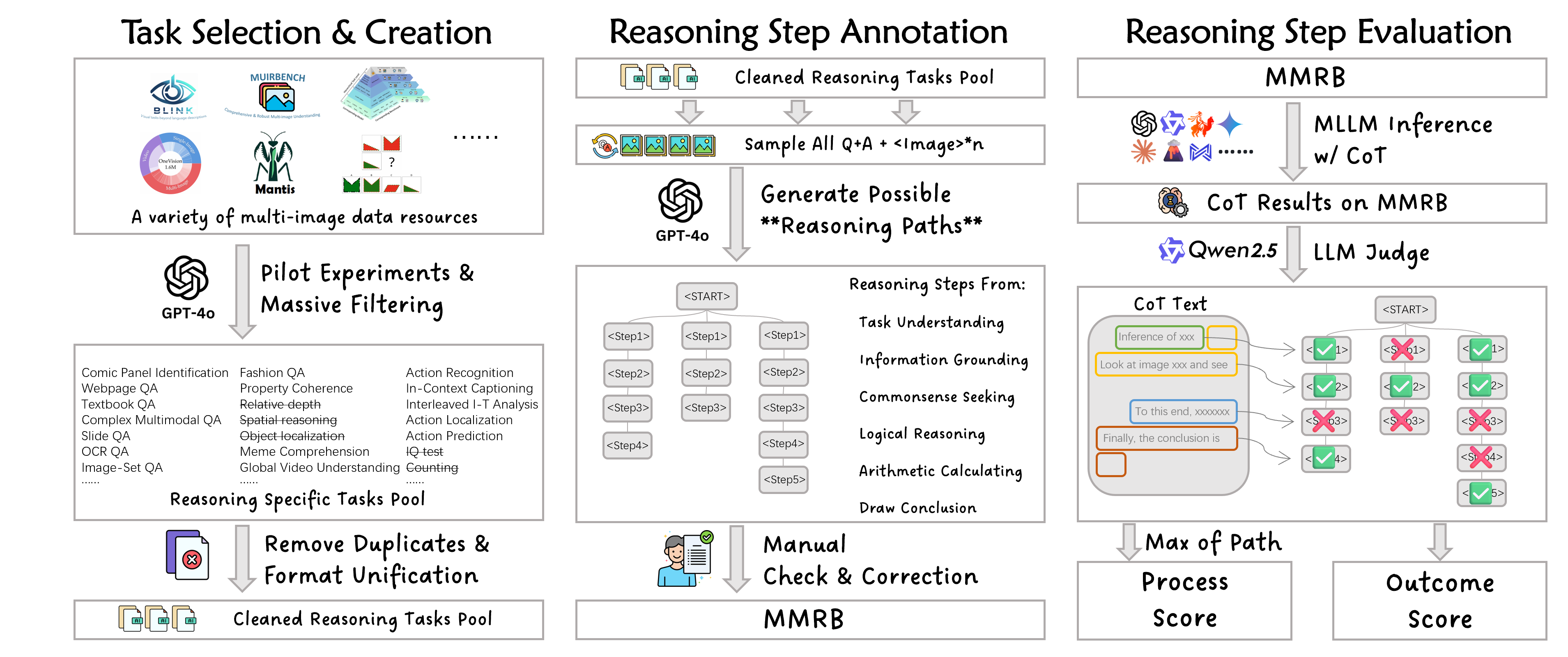
With enhanced capabilities and widespread applications, Multi-modal Large Language Models (MLLMs) are increasingly required to process and reason over multiple images simultaneously. However, existing MLLM benchmarks focus either on single-image visual reasoning or on multi-image understanding tasks with only final-answer evaluation, leaving the reasoning capabilities of MLLMs over multi-image inputs largely underexplored. To address this gap, we introduce the Multimodal Multi-image Reasoning Benchmark (MMRB), the first benchmark designed to evaluate structured visual reasoning across multiple images. MMRB comprises 92 sub-tasks covering spatial, temporal, and semantic reasoning, with multi-solution, CoT-style annotations generated by GPT-4o and refined by human experts. A derivative subset is designed to evaluate multimodal reward models in multi-image scenarios. To support fast and scalable evaluation, we propose a sentence-level matching framework using open-source LLMs. Extensive baseline experiments on 40 MLLMs, including 9 reasoning-specific models and 8 reward models, demonstrate that open-source MLLMs still lag significantly behind commercial MLLMs in multi-image reasoning tasks. Furthermore, current multimodal reward models are nearly incapable of handling multi-image reward ranking tasks.
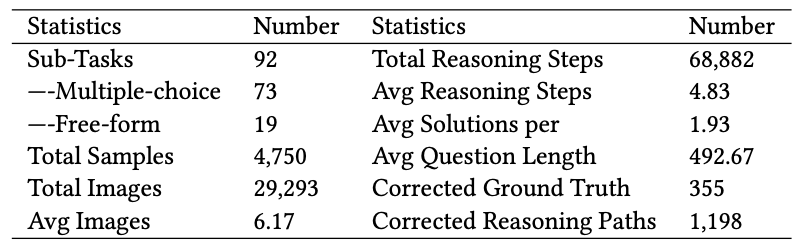
We first present an overview of our Multimodal Multi-image Reasoning Benchmark. Our benchmark consists of 4,750 samples encompassing 68,882 reasoning steps across 92 sub-tasks, covering semantic, spatial, and temporal reasoning. Notably, each sample contains an average of 6.17 images and 1.93 distinct solutions. During the annotation process, we also corrected a horrifying 355 incorrect ground truths from the source datasets, which could have resulted in up to a 14% deviation in our benchmark if left uncorrected.
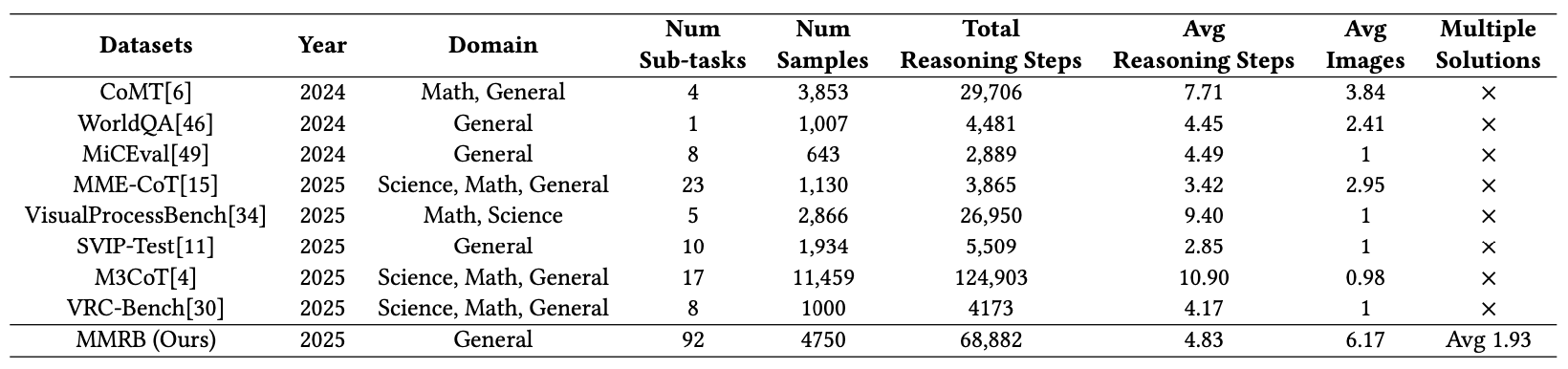
MMRB stands out as the largest benchmark by sub-task count and image density, the only one to offer multiple-solution annotations.
Non-reasoning-specialized API Model Reasoning-specialized API Model
Non-reasoning-specialized Open-source Model Reasoning-specialized Open-source Model
| Reset | |||||
|---|---|---|---|---|---|
| Model | Outcome Score | Outcome Score \w CoT | Process Score | Efficacy Score | |
Overall results of different models on the MMRB leaderboard. The best-performing model in each category is in-bold, and the second best is underlined.

IQ Test

Face Retrieval

Webpage QA

Geopraphic Understanding

MathVerse

Comic Panel Identification

Visual Cloze

Visual Referring
@article{cheng2025evaluating,
title={Evaluating MLLMs with Multimodal Multi-image Reasoning Benchmark},
author={Cheng, Ziming and Xu, Binrui and Gong, Lisheng and Song, Zuhe and Zhou, Tianshuo and Zhong, Shiqi and Ren, Siyu and Chen, Mingxiang and Meng, Xiangchao and Zhang, Yuxin and others},
journal={arXiv preprint arXiv:2506.04280},
year={2025}
}